Off-Policy Learning

On-policy ⇒ Exploitation
- Learning fast
- But may miss the best policy in a long run
- 결과가 잘 나온 곳 근처만 계속 판다.
Off-policy ⇒ Exploration
- Learning slow
- Explore diverse actions for finding the best policy.
- 다양한 곳을 다 판다.
E [x^2] Following Laplace Distribution
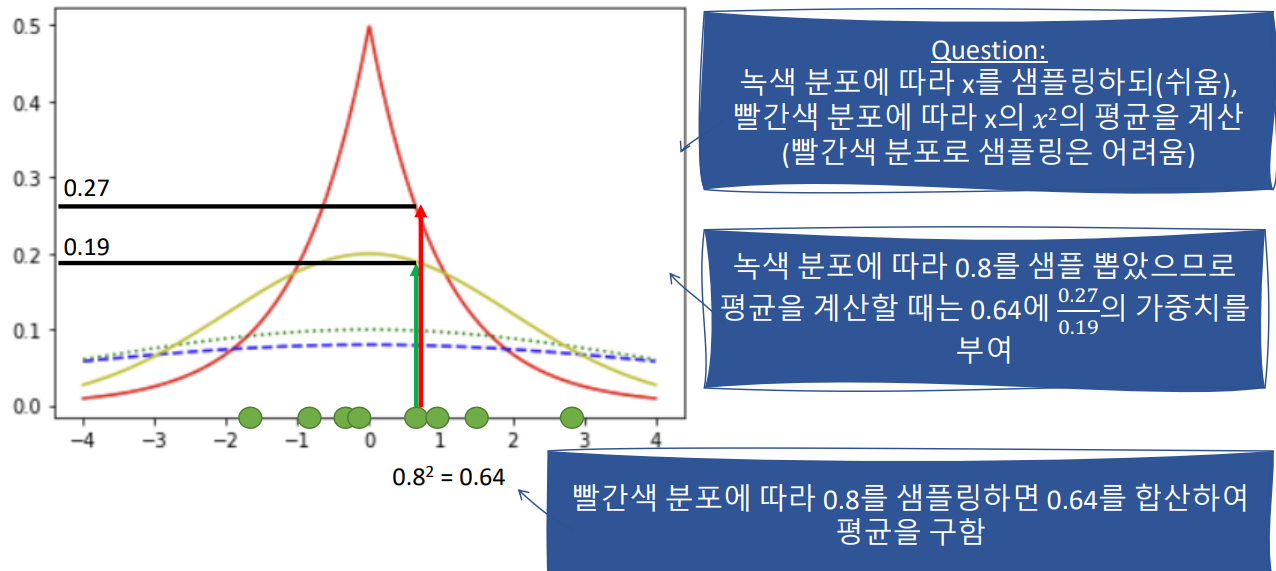
1. 중심 극한 정리 : 가우시안 분포를 따르는 샘플을 추출.
2. 이후, 해당 값x는 우리가 원하는 분포(빨간색 그래프) y값 만큼의 가중치를 준다.
3. 그럼, 빨간색 분포를 다르는 샘플을 얻을 수 있다.
비교적 안정적이고 정확한 Policy가 나온다.

'AI & Data Analysis' 카테고리의 다른 글
| Metropolitan Museum of Art 데이터 다운하기 (0) | 2025.02.14 |
|---|---|
| [Reinforcement] Temporal-Difference RL (Bootstrapping Approaches) (5) | 2025.01.25 |
| [PDFMathTranslate] 영어 논문 번역하는 방법 (1) | 2025.01.24 |
| [Backpropagation] (0) | 2025.01.23 |
| [Reinforcement] MDP, Monte-Carlo RL (0) | 2025.01.23 |



