https://arxiv.org/abs/2211.09800
InstructPix2Pix: Learning to Follow Image Editing Instructions
We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the
arxiv.org
Background
Diffusion Model,
Conditional Diffusion Model : 원본 이미지 x → 잠재 공간 → noise가 추가되는 Diffusion Model ; 조건이 반영되며 de noising 과정 반복
Introduction
이전에 본 적 없는 이미지에 대해서 결과를 도출하는 zero-shot도 가능
Prior work
거대한 두가지 모델을 결합하여, 두 가지 training 모델을 만듦
편집할 부분을 mask로 지정해줘야하는데, 전체적인 무드 변환이 불가능하다는 단점을 보완
Method
- 거대한 모델 결합하여 trainning 모델 만들기?
- 어떻게 learning?
- input 이미지 → 지시 → 지시 기반 output이미지
- 적절한 p 값을 찾기 어려우므로, 캡션당 이미지 100개 생성 후, CLIP 기반 방향 유사성 지표로 최대 4개의 데이터 필터링
- Prompt - to - Prompt 사용으로 데이터가 완강해짐

x축 증가 방향 :
text 지시에 대한 일관성이 높아져서, 지시에 대해 공격적으로 변함
y축 증가 방향 :
이전 이미지에서, 크게 변하지 않는 방향으로 변화한다.
Results

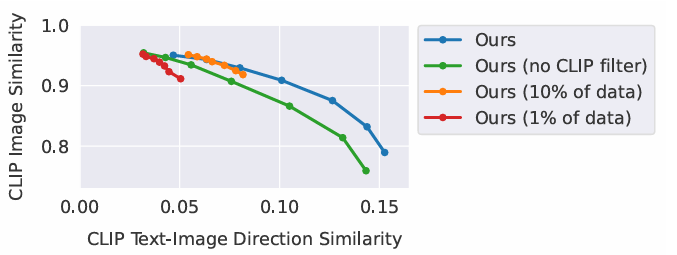
초록색 : 필터링을 아예 하지 않음 : 이미지 일관성이 큰 폭으로 떨어짐.
주황색 : 데이터를 10% 줄임.
빨간색 : 데이터를 1% 줄임.
결국은 양질의 데이터를 다량으로 확보하는 것이 중요하다.
Discussion
Limitations : 사람이 말하는 지시와, AI 가 받아들이는 지시 사이에 차이가 존재한다.
- 화질이 좋지 못하다.
- GPT-3와 Prompt-to-Prompt의 한계로 정확한 연관성을 갖지 못함
- 객체의 수, 공간적 추론, 학습 데이터의 편항을 그대로 “상속”을 받음
추가 사항
prompt-to-ptompt를 사용함으로써, 일관성을 유지.
원문 논문 :
한국어 번역 논문 :
'AI & Data Analysis > Paper Reviews' 카테고리의 다른 글
| Zero-Shot Text-to-Image Generation (DALL-E) (1) | 2025.01.31 |
|---|---|
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2) | 2025.01.31 |
| Language Models are Few-Shot Learners (1) | 2025.01.31 |
| [GSEA] Paper review detail (1) | 2024.10.11 |
| Transcriptome analysis based on machine learning reveals a role for autoinflamma (0) | 2024.07.02 |



