Simple neighborhood aggregation 개념을 바탕으로
attention을 적용한, Graph Attention Network (GAT) 의 구조를 살펴보자.
Simple neighborhood aggregation
Simple neighborhood aggregation
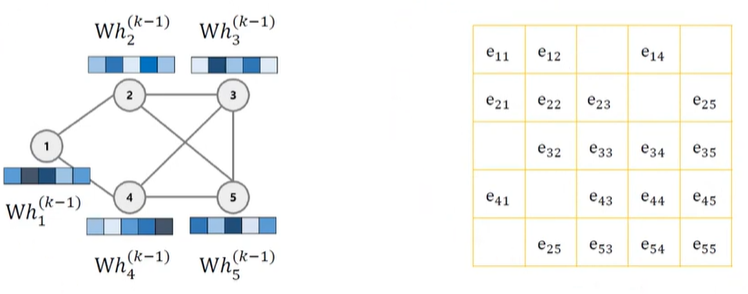
Node i 에 대한 Node Computation Graph $h_v^k$ : **노드 vv**의 $k$번째 layer의 임베딩 (출력)$h_u^{k-1}$: 이웃 노드 $u$의 이전 layer의 임베딩 (입력)$N(v)$: 노드 $v$의 이웃 집합$W_k, B_k$: 각각 이웃 정보, 자기 자신
doraemin.tistory.com
Simple neighborhood aggregation

Graph Attention Network (GAT)

- Attention Coefficients $𝛼_{𝑣𝑢}$를 적용
- 각 Neighborhood Node의 중요도를 다르게 ($≠1⁄|𝑁(𝑣)|$ )
1. Input
각 노드 𝑖의 특징 벡터 : $ℎ ⃗_𝑖∈𝑅^𝐹$
모든 노드에 공통된 가중치 행렬 $𝑊∈𝑅^{𝐹^′×𝐹}$를 적용해 변환
2. Self-Attention (이웃 노드 간 중요도 학습)
노드 𝑖와 이웃 노드 𝑗 사이의 관계를 attention 함수로 계산 : $𝑒_{𝑖𝑗}=𝑎( 𝑊 ℎ ⃗_𝑖, 𝑊 ℎ ⃗_𝑗 ) $
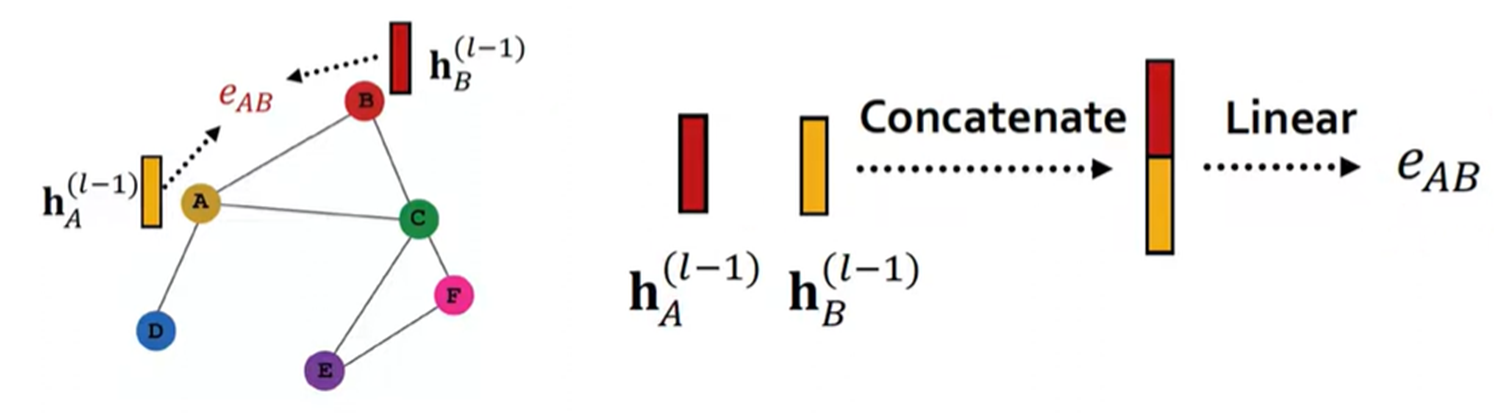
구현: 𝑎는 단일 층 MLP + LeakyReLU
$𝛼_{𝑖𝑗}=𝑠𝑜𝑓𝑡𝑚𝑎𝑥_𝑗 (𝑒_{𝑖𝑗} )= softmax_𝑗 ( 𝐿𝑒𝑎𝑘𝑦𝑅𝑒𝐿𝑈 (𝑎 ⃗^𝑇 [𝑊ℎ ⃗_𝑖∥𝑊ℎ ⃗_𝑗 ]) )$

3. Aggregation
학습된 $α_ij$ 를 사용하여 이웃 노드로부터 가중 평균:

4. Multi-Head Attention (병렬 Attention)
𝐾개의 서로 다른 attention head를 사용


출처/참고
'AI & Data Analysis > Deep Learning' 카테고리의 다른 글
| [ScRAT Dataset] compare in cellxgene (0) | 2025.07.23 |
|---|---|
| [GAT] self-attention (0) | 2025.07.17 |
| Simple neighborhood aggregation (0) | 2025.07.09 |
| [HierMIL Dataset] compare in cellxgene (0) | 2025.06.24 |
| Pretrained model vs. Transfer learning (0) | 2025.06.09 |



