# 1. 원-핫 인코딩 적용
import pandas as pd
class2 = pd.read_csv("/content/class2.csv")
print(class2)
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
train_x= label_encoder.fit_transform(class2['class2'])
train_x
# Unnamed: 0 id tissue class class2 x y r
# 0 0 CID000 C CIRC N 535.0 475.0 192.0
# 1 1 CID001 A CIRA N 433.0 268.0 58.0
# 2 2 CID002 A CIRA I NaN NaN NaN
# 3 3 CID003 C CIRC B NaN NaN NaN
# 4 4 CID004 F CIRF I 488.0 145.0 29.0
# 5 5 CID005 C CIRC B 532.0 199.0 21.0
# array([2, 2, 1, 0, 1, 0])
# 2. 코퍼스에 카운터 벡터 적용
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vect = CountVectorizer()
vect.fit(corpus)
vect.vocabulary_
# {'this': 8,
# 'is': 3,
# 'the': 6,
# 'first': 2,
# 'document': 1,
# 'second': 5,
# 'and': 0,
# 'third': 7,
# 'one': 4}# 3. 배열 변환
vect.transform(['This document is the second document.']).toarray()
# array([[0, 2, 0, 1, 0, 1, 1, 0, 1]])# 4. 불용어를 제거한 카운터 벡터
vect = CountVectorizer(stop_words=["and", "is", "the", "this"]).fit(corpus)
vect.vocabulary_
# {'first': 1, 'document': 0, 'second': 3, 'third': 4, 'one': 2}# 5. TF-IDF를 적용한 후 행렬로 표현
# TF(Term Frequency)(단어 빈도)는 문서 내에서 특정 단어가 출현한 빈도를 의미
# DF는 한 단어가 전체 문서에서 얼마나 공통적으로 많이 등장하는지 나타내는 값. 즉, 특정 단어가 나타난 문서 개수라고 이해하면 됨
# DF 값이 클수록 TF-IDF의 가중치 값을 낮추기 위해 DF 값에 역수를 취하는데, 이 값이 IDF
# 역수를 취하면 전체 문서 개수가 많아질수록 IDF 값도 커지므로 IDF는 로그(log)를 취해야 함
from sklearn.feature_extraction.text import TfidfVectorizer
doc = ['I like machine learning', 'I love deep learning', 'I run everyday']
tfidf_vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')
tfidf_matrix = tfidf_vectorizer.fit_transform(doc)
doc_distance = (tfidf_matrix * tfidf_matrix.T)
print('유사도를 위한', str(doc_distance.get_shape()[0]), 'x', str(doc_distance.get_shape()[1]), 'matrix를 만들었습니다.')
print(doc_distance.toarray())
# 유사도를 위한 3 x 3 matrix를 만들었습니다.
# [[1. 0.224325 0. ]
# [0.224325 1. 0. ]
# [0. 0. 1. ]]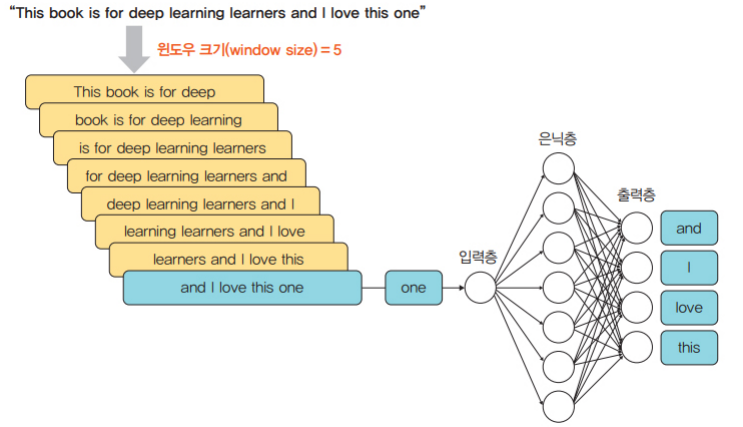
# 6. 데이터셋을 메모리로 로딩하고 토큰화 적용
# pip install nltk gensim
import nltk
nltk.download('punkt_tab')
# 6. 데이터셋을 메모리로 로딩하고 토큰화 적용
from nltk.tokenize import word_tokenize, sent_tokenize # Import sent_tokenize here
import warnings
warnings.filterwarnings(action='ignore')
import gensim
from gensim.models import Word2Vec
sample = open('/content/peter.txt', "r", encoding='UTF8')
s = sample.read()
f = s.replace('\n', ' ')
data = []
for i in sent_tokenize(f):
temp = []
for j in word_tokenize(i):
temp.append(j.lower())
data.append(temp)
print(data)
# [['once', 'upon', 'a', 'time', 'in', 'london', ',', 'the', 'darlings', 'went', 'out', 'to', 'a', 'dinner', 'party', 'leaving', 'their', 'three', 'children', 'wendy', ',', 'jhon', ',', 'and', 'michael', 'at', 'home', '.'], ['after', 'wendy', 'had', 'tucked', 'her', 'younger', 'brothers', 'jhon', 'and', 'michael', 'to', 'bed', ',', 'she', 'went', 'to', 'read', 'a', 'book', '.'], ['she', 'heard', 'a', 'boy', 'sobbing', 'outside', 'her', 'window', '.'], ['he', 'was', 'flying', '.'], ['there', 'was', 'little', 'fairy', 'fluttering', 'around', 'him', '.'], ['wendy', 'opened', 'the', 'window', 'to', 'talk', 'to', 'him', '.'], ['“', 'hello', '!'], ['who', 'are', 'you', '?'], ['why', 'are', 'you', 'crying', '”', ',', 'wendy', 'asked', 'him', '.'], ['“', 'my', 'name', 'is', 'peter', 'pan', '.'], ['my', 'shadow', 'wouldn', '’', 't', 'stock', 'to', 'me.', '”', ',', 'he', 'replied', '.'], ['she', 'asked', 'him', 'to', 'come', 'in', '.'], ['peter', 'agreed', 'and', 'came', 'inside', 'the', 'room', '.'], ['wendy', 'took', 'his', 'shadow', 'and', 'sewed', 'it', 'to', 'his', 'shoe', 'tips', '.'], ['now', 'his', 'shadow', 'followed', 'him', 'wherever', 'peter', 'pan', 'went', '!'], ['he', 'was', 'delighted', 'and', 'asked', 'wendy', '“', 'why', 'don', '’', 't', 'you', 'come', 'with', 'me', 'to', 'my', 'home', '.'], ['the', 'neverland', '.'], ['i', 'lived', 'there', 'with', 'my', 'fairy', 'tinker', 'bell.', '”', 'wendy', '?'], ['“', 'oh', '!'], ['what', 'a', 'wonderful', 'idea', '!'], ['let', 'me', 'wake', 'up', 'john', 'and', 'micheal', 'too', '.'], ['could', 'you', 'teach', 'us', 'how', 'to', 'fly', '?', '”', '.'], ['“', 'yes', '!'], ['of', 'course', '!'], ['get', 'them', 'we', 'will', 'all', 'fly', 'together.', '”', 'peter', 'pan', 'replied', 'and', 'so', 'it', 'was', '.'], ['five', 'little', 'figures', 'flew', 'out', 'of', 'the', 'window', 'of', 'the', 'darlings', 'and', 'headed', 'towards', 'neverland', '.'], ['as', 'they', 'flew', 'over', 'the', 'island', ',', 'peter', 'pan', 'told', 'the', 'children', 'more', 'about', 'his', 'homeland', '.'], ['“', 'all', 'the', 'children', 'who', 'get', 'lost', 'come', 'and', 'stay', 'with', 'tinker', 'bell', 'and', 'me', ',', '”', 'peter', 'told', 'them', '.'], ['the', 'indians', 'also', 'live', 'in', 'neverland', '.'], ['the', 'mermaids', 'live', 'in', 'the', 'lagoon', 'around', 'the', 'island', '.'], ['and', 'a', 'very', 'mean', 'pirate', 'called', 'captain', 'hook', 'keeps', 'troubling', 'everyone', '.'], ['“', 'crocodile', 'bit', 'his', 'one', 'arm', '.'], ['so', 'the', 'captain', 'had', 'to', 'put', 'a', 'hook', 'in', 'its', 'place', '.'], ['since', 'then', 'he', 'is', 'afraid', 'of', 'crocodiles', '.'], ['and', 'rightly', 'so', '!'], ['if', 'the', 'crocodile', 'ever', 'found', 'captain', 'hook', 'it', 'will', 'eat', 'up', 'the', 'rest', 'of', 'it', 'couldn', '’', 't', 'eat', 'last', 'time.', '”', 'peter', 'told', 'them', '.'], ['soon', 'they', 'landed', 'on', 'the', 'island', '.'], ['and', 'to', 'the', 'surprise', 'of', 'wendy', ',', 'jhon', 'and', 'michael', ',', 'peter', 'pan', 'let', 'them', 'in', 'through', 'a', 'small', 'opening', 'in', 'a', 'tree', '.'], ['inside', 'the', 'tree', 'was', 'a', 'large', 'room', 'with', 'children', 'inside', 'it', '.'], ['somewhere', 'huddled', 'by', 'the', 'fire', 'in', 'the', 'corner', 'and', 'somewhere', 'playing', 'amongst', 'themselves', '.'], ['their', 'faces', 'lit', 'up', 'when', 'they', 'saw', 'peter', 'pan', ',', 'tinker', 'bell', ',', 'and', 'their', 'guests', '.'], ['“', 'hello', 'everyone', '.'], ['this', 'is', 'wendy', ',', 'jhon', ',', 'and', 'michael', '.'], ['they', 'will', 'be', 'staying', 'with', 'us', 'from', 'now', 'on.', '”', 'peter', 'pan', 'introduced', 'them', 'to', 'all', 'children', '.'], ['children', 'welcomed', 'wendy', ',', 'jhon', ',', 'and', 'michael', '.'], ['a', 'few', 'days', 'passed', '.'], ['and', 'they', 'settled', 'into', 'a', 'routine', '.'], ['wendy', 'would', 'take', 'care', 'of', 'all', 'the', 'children', 'in', 'the', 'day', 'and', 'would', 'go', 'out', 'with', 'peter', 'pan', 'and', 'her', 'brothers', 'in', 'the', 'evening', 'to', 'learn', 'about', 'the', 'island', '.'], ['she', 'would', 'cook', 'for', 'them', 'and', 'stitch', 'new', 'clothes', 'for', 'them', '.'], ['he', 'even', 'made', 'a', 'lovely', 'new', 'dress', 'for', 'tinker', 'bell', '.'], ['one', 'evening', ',', 'as', 'they', 'were', 'out', 'exploring', 'the', 'island', 'peter', 'pan', 'warned', 'everyone', 'and', 'said', ',', '“', 'hide', '!'], ['hide', '!'], ['pirates', '!'], ['and', 'they', 'have', 'kidnapped', 'the', 'indian', 'princess', 'tiger', 'lily', '.'], ['they', 'have', 'kept', 'her', 'there', ',', 'tied', 'up', 'by', 'the', 'rocks', ',', 'near', 'the', 'water.', '”', 'peter', 'was', 'afraid', 'and', 'the', 'princess', 'would', 'drown', ',', 'is', 'she', 'fell', 'into', 'the', 'water', '.'], ['so', ',', 'in', 'a', 'voice', 'that', 'sounded', 'like', 'captain', 'hook', ',', 'he', 'shouted', 'instructions', 'to', 'the', 'pirates', 'who', 'guarded', 'her', ',', '“', 'you', 'fools', '!'], ['let', 'her', 'go', 'at', 'once', '!'], ['do', 'it', 'before', 'i', 'come', 'there', 'or', 'else', 'i', 'will', 'throw', 'each', 'one', 'of', 'you', 'into', 'the', 'water.', '”', 'the', 'pirates', 'got', 'scared', 'and', 'immediately', 'released', 'the', 'princes', '.'], ['she', 'quickly', 'dived', 'into', 'the', 'water', 'and', 'swam', 'to', 'the', 'safety', 'of', 'her', 'home', '.'], ['soon', 'everyone', 'found', 'out', 'how', 'peter', 'pan', 'had', 'rescued', 'the', 'princess', '.'], ['when', 'captain', 'hook', 'found', 'out', 'how', 'peter', 'had', 'tricked', 'his', 'men', 'he', 'was', 'furious', '.'], ['and', 'swore', 'to', 'have', 'his', 'revenge', '.'], ['that', 'night', 'wendy', 'told', 'peter', 'pan', ',', 'that', 'she', 'and', 'her', 'brother', 'wanted', 'to', 'go', 'back', 'home', 'since', 'they', 'missed', 'their', 'parents', '.'], ['she', 'said', 'if', 'the', 'lost', 'children', 'could', 'also', 'return', 'to', 'her', 'world', 'they', 'could', 'find', 'a', 'nice', 'home', 'for', 'them', '.'], ['peter', 'pan', 'didn', '’', 't', 'want', 'to', 'leave', 'neverland', '.'], ['but', 'the', 'sake', 'of', 'the', 'lost', 'children', 'he', 'agreed', ',', 'although', 'a', 'bit', 'sadly', '.'], ['he', 'would', 'miss', 'his', 'friends', 'dearly', '.'], ['the', 'next', 'morning', 'all', 'the', 'lost', 'children', 'left', 'with', 'wendy', ',', 'jhon', ',', 'and', 'michael', '.'], ['but', 'on', 'the', 'way', ',', 'captain', 'hook', 'and', 'his', 'men', 'kidnapped', 'all', 'of', 'them', '.'], ['he', 'tied', 'them', 'and', 'kept', 'them', 'on', 'once', 'of', 'his', 'ships', '.'], ['as', 'soon', 'as', 'peter', 'found', 'out', 'about', 'it', 'he', 'rushed', 'to', 'the', 'ship', '.'], ['he', 'swung', 'himself', 'from', 'a', 'tress', 'branch', 'and', 'on', 'to', 'the', 'deck', 'of', 'the', 'ship', 'where', 'all', 'the', 'children', 'were', 'tied', 'up', '.'], ['he', 'swung', 'his', 'sword', 'bravely', 'and', 'threw', 'over', 'the', 'pirates', 'who', 'tried', 'to', 'stop', 'him', '.'], ['quickly', 'he', 'released', 'everyone', 'from', 'their', 'captor', '’', 's', 'ties', '.'], ['wendy', ',', 'jhon', ',', 'michael', 'and', 'tinker', 'bell', 'helped', 'all', 'the', 'children', 'into', 'the', 'water', ',', 'where', 'their', 'friends', 'from', 'the', 'indian', 'camp', 'were', 'ready', 'with', 'smaller', 'boats', 'to', 'take', 'them', 'to', 'safety', 'peter', 'pan', 'now', 'went', 'looking', 'for', 'captain', 'hook', '.'], ['“', 'let', 'us', 'finished', 'this', 'forever', 'mr.', 'hook', '”', ',', 'peter', 'challenged', 'captain', 'hook', '.'], ['“', 'yes', '!'], ['peter', 'pan', ',', 'you', 'have', 'caused', 'me', 'enough', 'trouble', '.'], ['it', 'is', 'time', 'that', 'we', 'finished', 'this.', '”', 'hook', 'replied', '.'], ['with', 'his', 'sword', 'drawn', ',', 'he', 'raced', 'towards', 'peter', 'pan', '.'], ['quick', 'on', 'his', 'feet', ',', 'peter', 'pan', 'stepped', 'aside', 'and', 'pushed', 'hook', 'inside', 'the', 'sea', 'where', 'the', 'crocodile', 'was', 'waiting', 'to', 'eat', 'the', 'rest', 'of', 'hook', '.'], ['everyone', 'rejoiced', 'as', 'captain', 'hook', 'was', 'out', 'of', 'their', 'lives', 'forever', '.'], ['everybody', 'headed', 'back', 'to', 'london', '.'], ['mr.', 'and', 'mrs', '.'], ['darling', 'was', 'so', 'happy', 'to', 'see', 'their', 'children', 'and', 'they', 'agreed', 'to', 'adopt', 'the', 'lost', 'children', '.'], ['they', 'even', 'asked', 'peter', 'pan', 'to', 'come', 'and', 'live', 'with', 'them', '.'], ['but', 'peter', 'pan', 'said', ',', 'he', 'never', 'wanted', 'to', 'grow', 'up', ',', 'so', 'he', 'and', 'tinker', 'bell', 'will', 'go', 'back', 'to', 'neverland', '.'], ['peter', 'pan', 'promised', 'everyone', 'that', 'he', 'will', 'visit', 'again', 'sometime', '!'], ['and', 'he', 'flew', 'out', 'of', 'the', 'window', 'with', 'tinker', 'bell', 'by', 'his', 'side', '.']]


# 7. 데이터셋에 CBOW 적용 후 'peter'와 'wendy'의 유사성 확인
# CBOW(Continuous Bag Of Words)는 단어를 여러 개 나열한 후 이와 관련된 단어를 추정하는 방식
# 예를 들어 “calm cat slept on the sofa”라는 문장이 있을 때, “calm cat____ on the sofa”라는 문맥이 주어지면 “slept”를 예측하는 것이 CBOW
# W'(5 * 7) * 입력층(7 * 1) = 출력층(5 * 1)
from gensim.models import Word2Vec
model1 = gensim.models.Word2Vec(data, min_count=1, vector_size=100, window=5, sg=0)
print("Cosine similarity between 'peter'" + "'wendy' - CBOW", model1.wv.similarity('peter', 'wendy'))
# Cosine similarity between 'peter''wendy' - CBOW 0.074393824# 8. 데이터셋에 CBOW 적용 후 'peter'와 'hook'의 유사성 확인
print("Cosine similarity between 'peter'" + "'hook' - CBOW", model1.wv.similarity('peter', 'hook'))
# Cosine similarity between 'peter''hook' - CBOW 0.027709836
# 9. 데이터셋에 skip-gram 적용 후 'peter'와 'wendy'의 유사성 확인
# skip-gram 방식은 CBOW 방식과 반대로 특정한 단어에서 문맥이 될 수 있는 단어를 예측
# 예를 들어 다음 그림과 같이 중심 단어 ‘slept’를 이용하여 그 앞과 뒤의 단어들을 유추하는 것이 skip-gram
model2 = gensim.models.Word2Vec(data, min_count=1, vector_size=100, window=5, sg=1)
print("Cosine similarity between 'peter'" + "'wendy' - Skip Gram", model2.wv.similarity('peter', 'wendy'))
# Cosine similarity between 'peter''wendy' - Skip Gram 0.40088683# 10. 데이터셋에 Skip Gram 적용 후 'peter'와 'hook'의 유사성 확인
print("Cosine similarity between 'peter'" + "'hook' - Skip Gram", model2.wv.similarity('peter', 'hook'))
# Cosine similarity between 'peter''hook' - Skip Gram 0.5201673# 11. Gensim을 이용하여 패스트텍스트
# 패스트텍스트(FastText)는 워드투벡터의 단점을 보완하고자 페이스북에서 개발한 임베딩 알고리즘
# 기존 워드투벡터의 워드 임베딩 방식은 분산 표현(distributed representation)을 이용하여 단어의 분산 분포가 유사한 단어들에 비슷한 벡터 값을 할당하여 표현
# 패스트텍스트는 노이즈에 강하며, 새로운 단어에 대해서는 형태적 유사성을 고려한 벡터 값을 얻기 때문에 자연어 처리 분야에서 많이 사용되는 알고리즘
from gensim.test.utils import common_texts
from gensim.models import FastText
model = FastText('/content/peter.txt', vector_size=4, window=3, min_count=1, epochs=10)
sim_score = model.wv.similarity('peter','wendy')
print(sim_score)
# 0.4592452
sim_score = model.wv.similarity('peter','hook')
print(sim_score)
# 0.043825686https://fasttext.cc/docs/en/pretrained-vectors.html
fastText
Library for efficient text classification and representation learning
fasttext.cc

# 12. 사전 학습된 패스트텍스트는 fastText API 또는 Gensim을 이용
from __future__ import print_function
from gensim.models import KeyedVectors
model_kr = KeyedVectors.load_word2vec_format('/content/wiki.ko.vec') # vec 파일 경로 입력해주자.
find_similar_to = '노력'
for similar_word in model_kr.similar_by_word(find_similar_to):
print("Word: {0}, Similarity: {1: .2f}".format(similar_word[0], similar_word[1]))
similarities = model_kr.most_similar(positive=['동물','육식동물'], negative=['사람'])
print(similarities)
# Word: 노력함, Similarity: 0.80
# Word: 노력중, Similarity: 0.75
# Word: 노력만, Similarity: 0.72
# Word: 노력과, Similarity: 0.71
# Word: 노력의, Similarity: 0.69
# Word: 노력가, Similarity: 0.69
# Word: 노력이나, Similarity: 0.69
# Word: 노력없이, Similarity: 0.68
# Word: 노력맨, Similarity: 0.68
# Word: 노력보다는, Similarity: 0.68
# [('초식동물', 0.7804122567176819), ('거대동물', 0.7547270655632019), ('육식동물의', 0.7547166347503662), ('유두동물', 0.753511369228363), ('반추동물', 0.7470757961273193), ('독동물', 0.7466291785240173), ('육상동물', 0.746031641960144), ('유즐동물', 0.7450903654098511), ('극피동물', 0.7449344396591187), ('복모동물', 0.742434561252594)]
# 13. 글로브
# 글로브(GloVe, Global Vectors for Word Representation)는 횟수 기반의 LSA(Latent Semantic Analysis)(잠재 의미 분석)와 예측 기반의 워드투벡터 단점을 보완하기 위한 모델
# 글로브는 그 이름에서 유추할 수 있듯이 단어에 대한 글로벌 동시 발생 확률(global co-occurrence statistics) 정보를 포함하는 단어 임베딩 방법
# skip-gram 방법을 사용하되 통계적 기법이 추가된 것이라고 할 수 있음
import numpy as np
%matplotlib notebook
import matplotlib.pyplot as plt
plt.style.use('ggplot')
from sklearn.decomposition import PCA
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
from gensim.script.glove2word2vec import glove2word2vec
glove_file = datapath('') # 경로 지정하자.
word2vec_glove_file = get_tmpfile()
glove2word2vec(golve_file, word2vec_glove_file)
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
# 'bill'과 유사한 단어의 리스트를 반환
model.most_similar('bill')
# 'cherry'과 유사한 단어의 리스트를 반환
model.most_similar('cherry')
# 'cherry'와 관련성이 없는 단어의 리스트를 반환
model.most_similar(negative=['cherry'])
# 'woman', 'king'과 유사성이 높으면서 'man'과 관련성이 없는 단어를 반환
result = model.most_similar(positive=['woman', 'king'], negative=['man'])
print("{}: {:.4f}".format(*result[0]))
# 'australia', 'beer', 'france'와 관련성이 있는 단어를 반환
def analogy(x1, x2, y1):
result = model.most_similar(positive=[y1,x2], negative=[x1])
return result[0][0]
analogy('australia','beer','france')
# 'tall', 'tallest', 'long' 단어를 기반으로 새로운 단어를 유추
analogy('tall', 'tallest', 'long')
# breakfast cereal dinner lunch' 중 유사도가 낮은 단어를 반환
print(model.doesnt_match("breakfast cereal dinner lunch".split()))'AI & Data Analysis' 카테고리의 다른 글
| [Reinforcement] MDP, Monte-Carlo RL (0) | 2025.01.23 |
|---|---|
| [Deep Learning] 개념 및 실습 [모음/정리] + 회고 (0) | 2025.01.19 |
| Batch Effect, Batch Correction (0) | 2024.11.21 |
| RNA 데이터 생성 과정 (0) | 2024.11.20 |
| SRA Toolkit 사용해서 데이터 받기 (3) | 2024.11.06 |
