RAG란?
Query(질문)이 들어오면 q(x)로 임베딩, 이후 검색, Top-K 선택
한계점 : 검색 품질 제한, 단순 추론, 리소스 낭비
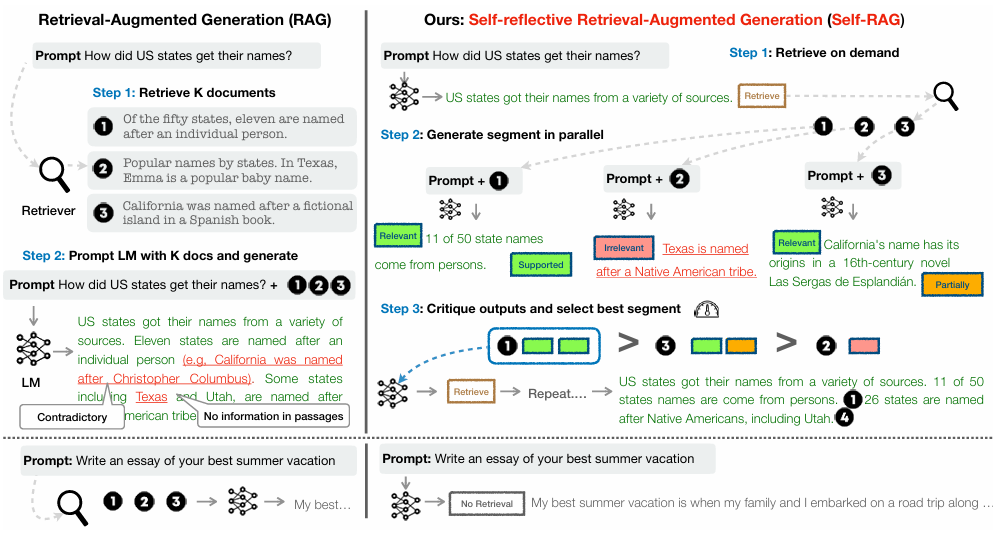
Introduction
답변 생성 시, 여러개가 도출.
SETP 1 : Retrieve on Demand ; Retrieve가 필요 여부 결정(실시간) 후 검색하든/하지않든
STEP 2 : Generate segment in parallel ; 각 segment마다 critique
REFLECTION TOKEN : Retrieve(검색 필요한가?), IsREL(관련성 판정), IsSUP(신뢰도 판정), IsUSE(답변 유용성 판정)
STEP 3
Method
Retrieve on Demand는 segment를 만들 때, 실시간으로 적용

장점
- 검색 품질 향상
- 자체 검증
- 추론 능력 강화
- 일관성 향상
한계점
- Retrieval 의존성
- 계산 복잡도 및 리소스 요구
- 특징 의존성
- 오류 전파 위험
Training
Retrieval : 양방향 인코더를 사용하여, 전체적으로 파악.
Generator : T5
Critique : GPT-4, llama2
⇒ 이제 Training
학습용 데이터셋 (Corpus) 생성 ; GPT-4로부터 “입력, 출력”쌍에 대한 Reflection tokens 수집.
Critic 학습
Experiements
Results and Analysis
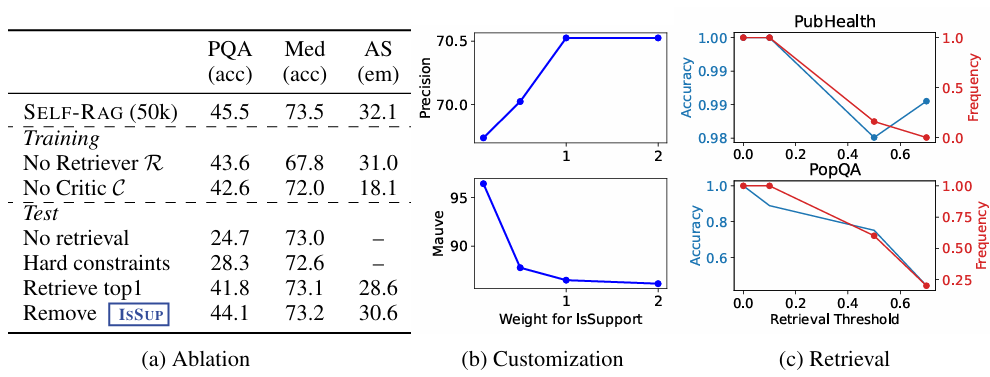
축소 연구 (Ablation Studies)
Inference Customization
- IsSUP 가중치 증가 시, Precision up Mauve down
- Train data size를 150K 이상시 추가 성능 향상 가능성
- Human Evaluation : S&P, IsREL, IsSUP에서 성능 좋다