# 합성곱 신경망 (CNN)
- 주로 이미지 데이터 학습할 때 사용
- 모든 학습은 오차역전파 알고리즘 -> 경사하강법
- 가중치가 학습되는 방식
- Momentum : 경사하강법에 Momentum(탄성)을 더해줌
- NAG : 직전 모멘텀 항에서 그레디언트를 계산하여 예측
- AdaGrad : 매 시점마다 별도의 학습률을 사용
- RMSprop : 최근 값의 영향은 크고, 오래된 값의 영향은 대폭 낮춤
- Adam : Momentum + RMSpropp ; 가장 좋은 성능, 가장 많이 사용됨
- DNN의 문제를 해결해 준다
- 복잡도 증가 시, 과적합 문제 발생
- 과적합 문제 해결 방법 존재
- 규제화
- 드롭아웃
- 배치 정규화 (미니배치, 공변량 변화)
- 합성곱 층(Layer)
- 입력층 : 이미지 데이터를 입력 ; Con2D(); 이전 DNN에서는 Flatten()으로 크기를 지정해줬는데, 그럴 필요가 이제 없다
- 첫번째 합성곱 층 : 모든 픽셀이 아닌, 수용장 안의 픽셀만 연결
- 두번째 합성곱 층 : 첫번째 층의 (작은/일부) 사각 영역에 위치한 뉴런에 연결
- 합성곱 연산
- 입력 데이터 중 일부(2*2) 부분이 필터를 통해, 하나의 값으로 출력 ; 패딩은 없던 데이터를 붙이기에, noise 발생
- 필터 : Kernel
- output = (FeatureMap - KernelSize + 2*Padding)/(strides) + 1
- Padding*2인 이유는, 상하좌우
- 폴링 Poling
- 2차원 데이터의 공간을 줄이는 연산
- 데이터 차원 감소 ; 계산 효율, 메모리 감소
- 불변성을 갖기 위해
- 흐름
- 학습 방식 : Convolution →ReLU → Pooling → Convolution → ReLU → Pooling → Fully
Connected
- Sequential → Conv1D → MaxPooling1D → Flatten → Dense → model.compile() ; Losses, Optimizers → model.fit()
- 성능 향상 방법 : Activation function뒤에 dropout을 적용 ,Batch normalization
- Conv Layer → Batch Normalization → Activation function → Pooling Layer
- 일반화
- 성능을 높이는 것이 목적
- fashion mnist 데이터로 CNN 분석
### fashion_mnist 데이터
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras import datasets, layers, models
# 1. 데이터 불러오기
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
print(train_images.shape, train_labels.shape)
print(test_images.shape, test_labels.shape)
train_images = train_images.reshape((60000, 28, 28, 1)) # 28*28 2차원 이미지 -> 흑백이미지를 28*
test_images = test_images.reshape((10000, 28, 28, 1))
# 2. 데이터 전처리
train_images = train_images / 255.0
test_images = test_images / 255.0
# 3. 모델 생성(CNN)
model = models.Sequential()
model.add(layers.Conv2D(
# filters=16, kernel_size= 3, strides=(1, 1), padding='same',
32, (3,3),
activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPool2D(pool_size=(2, 2))) #, strides=2
model.add(layers.Conv2D(
# filters=32, kernel_size= 3,strides=(1, 1), padding='same',
64,(3,3),
activation='relu'))
model.add(layers.MaxPool2D(pool_size=(2, 2))) #, strides=2
model.add(layers.Conv2D(
# filters=64, kernel_size= 3, strides=(1, 1), padding='same',
64, (3,3),
activation='relu'))
# model.add(layers.MaxPool2D(pool_size=(2, 2), strides=2))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation = 'relu')) # 3차원을 1차원으로 축소
model.add(layers.Dense(10, activation = 'softmax'))
model.summary()
# 파라미터 수 약 3만7천개
# DNN에서는 9만개정도였는데, 줄었다.
# 4. 모델 컴파일 및 학습
model.compile(optimizer='adam',
loss = 'categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, keras.utils.to_categorical(train_labels), epochs=5)
# 5. 모델 평가
test_loss, test_acc = model.evaluate(test_images, keras.utils.to_categorical(test_labels))
print(f"Test Accuracy: {test_acc}")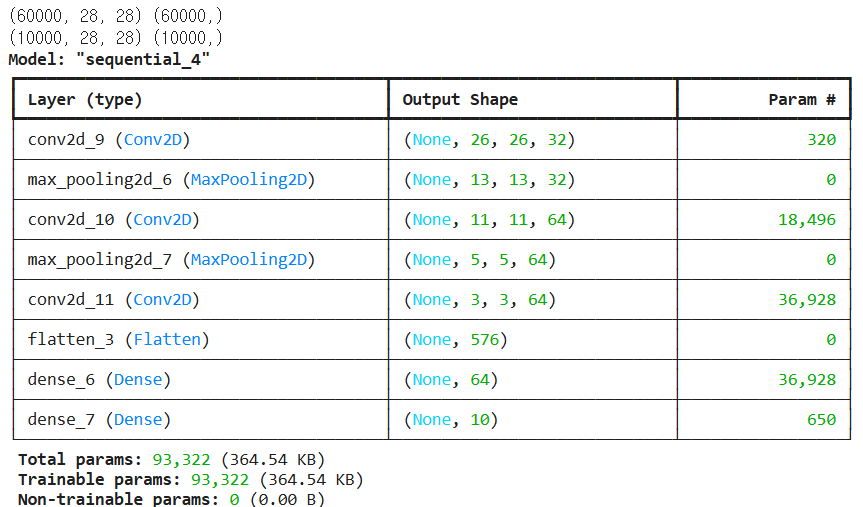
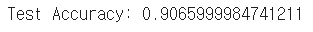
- MASK 데이터로 CNN 분석
### MASK 데이터
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split
# 이미지 데이터 경로 설정
base_dir = '/content/drive/MyDrive/Colab Notebooks/maskdetection/face_maskdetection'
# 데이터 전처리 및 분할
train_datagen = ImageDataGenerator(
rescale=1.0 / 255, # 픽셀 값을 0~1 범위로 조정
rotation_range=20, # 이미지 회전
width_shift_range=0.2, # 수평 방향 이동
height_shift_range=0.2, # 수직 방향 이동
shear_range=0.2, # 전단 변형
zoom_range=0.2, # 확대 축소
horizontal_flip=True,# 수평 뒤집기
fill_mode='nearest',
validation_split=0.2 # 80% 훈련, 20% 검증
)
train_generator = train_datagen.flow_from_directory(
base_dir,
target_size=(28, 28),
batch_size=32,
class_mode='categorical',
subset='training' # 훈련 데이터
)
validation_generator = train_datagen.flow_from_directory(
base_dir,
target_size=(28, 28),
batch_size=32,
class_mode='categorical',
subset='validation' # 검증 데이터
)
# 데이터 확인
print(f"Classes found: {train_generator.class_indices}") # Classes found: {'with_mask': 0, 'without_mask': 1}
print(f"Training samples: {train_generator.samples}") # Training samples: 1101
print(f"Validation samples: {validation_generator.samples}") # Validation samples: 275
print(train_generator.filenames[:5]) # 훈련 데이터 파일 이름 ; ['with_mask/24-with-mask.jpg', 'with_mask/240-with-mask.jpg', 'with_mask/241-with-mask.jpg', 'with_mask/242-with-mask.jpg', 'with_mask/243-with-mask.jpg']
print(validation_generator.filenames[:5]) # 검증 데이터 파일 이름 ; ['with_mask/0-with-mask.jpg', 'with_mask/1-with-mask.jpg', 'with_mask/10-with-mask.jpg', 'with_mask/100-with-mask.jpg', 'with_mask/101-with-mask.jpg']
### CNN ; model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 3)),
MaxPooling2D(2, 2),
Dropout(0.2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Dropout(0.2),
Conv2D(32, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Dropout(0.3),
Flatten(),
Dense(128, activation='relu'),
Dense(2, activation='softmax') # 클래스 수에 따라 변경 (2개 클래스: with_mask, without_mask)
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
epochs = 20
# 모델 학습
history = model.fit(
train_generator,
validation_data=validation_generator,
epochs=20,
)
# 모델 평가
test_loss, test_acc = model.evaluate(validation_generator)
print(f"Validation Loss: {test_loss}")
print(f"Validation Accuracy: {test_acc}")
import matplotlib.pyplot as plt
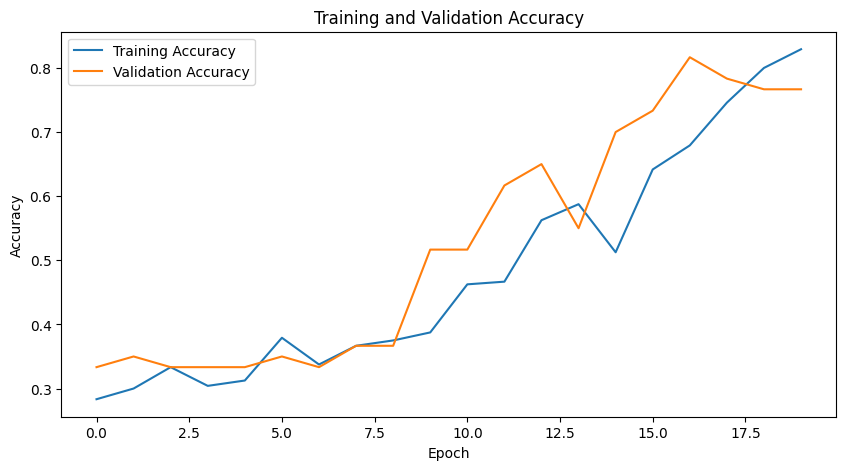
# 정확도 그래프
plt.figure(figsize=(10, 5))
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
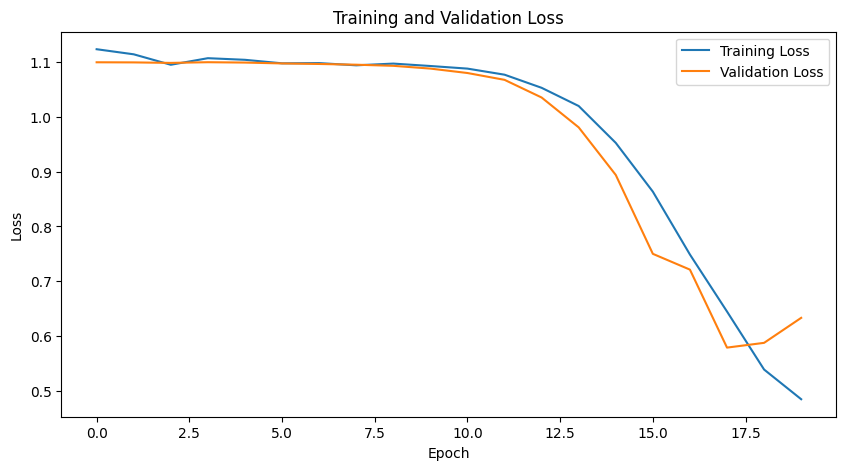
# 손실 그래프
plt.figure(figsize=(10, 5))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()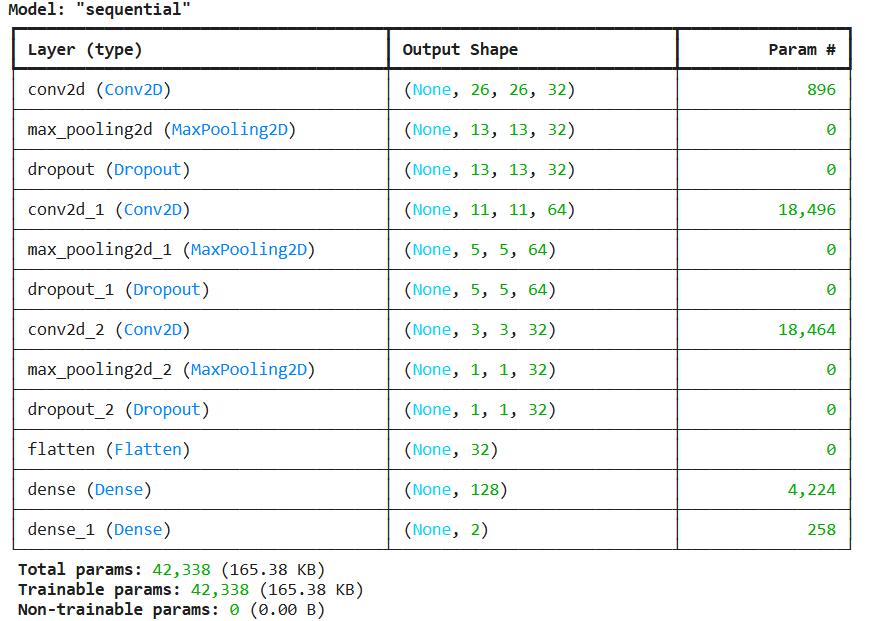

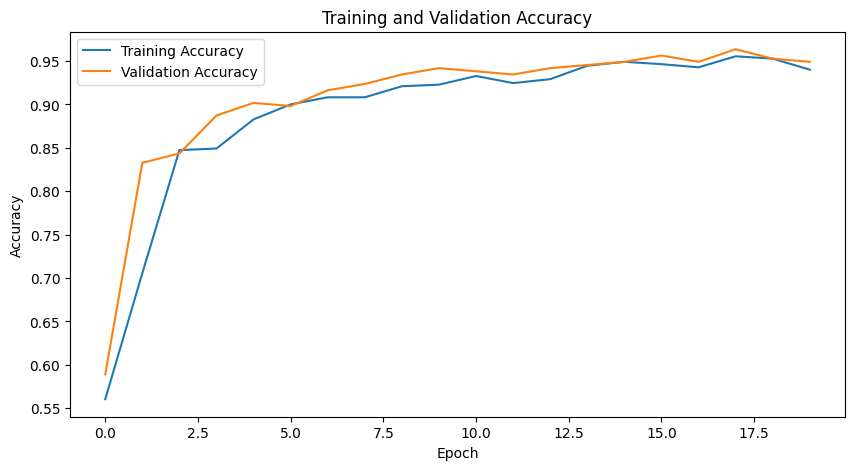
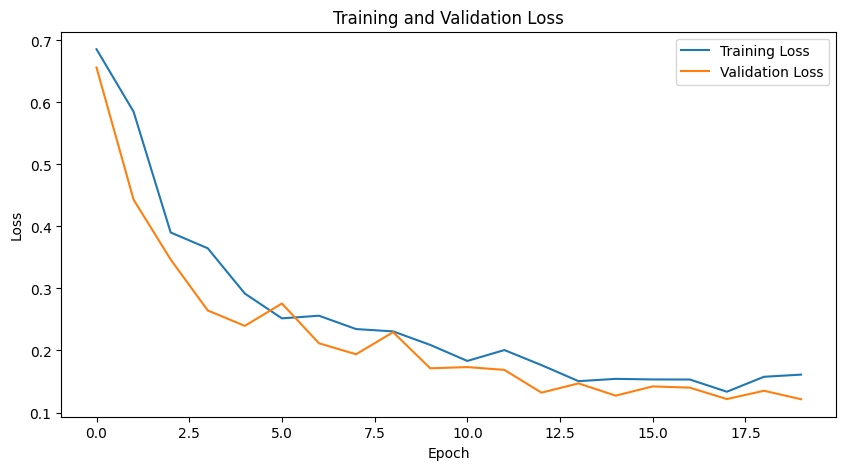
+ 추가로, Epoch 50번 실행 시, 약간 더 좋은 성능을 보인다.
Validation Loss: 0.11369598656892776
Validation Accuracy: 0.9672726988792419
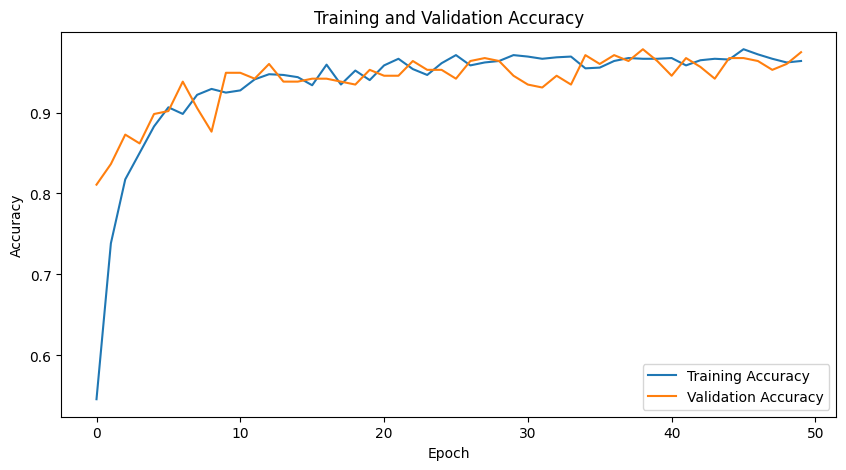
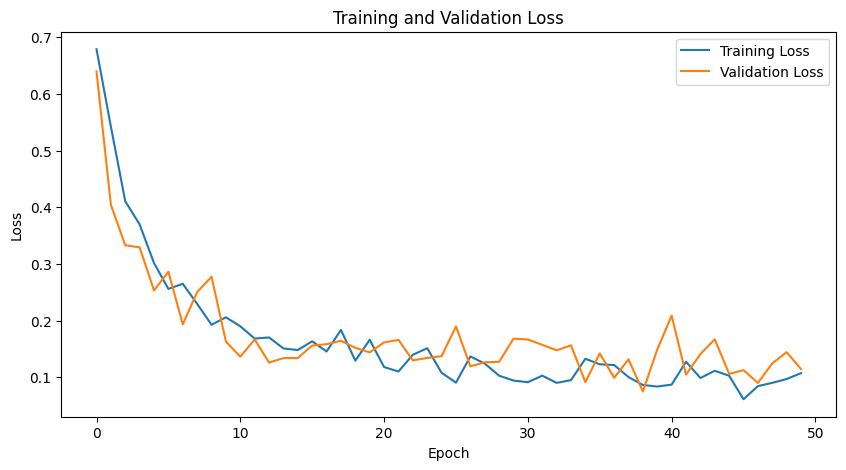
- Shape 데이터로 CNN 분
### Shape 데이터
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split
# 이미지 데이터 경로 설정
base_dir = '/content/drive/MyDrive/Colab Notebooks/shapes'
# 데이터 전처리 및 분할
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
validation_split=0.2 # 80% 훈련, 20% 검증
)
train_generator = train_datagen.flow_from_directory(
base_dir,
target_size=(28, 28),
batch_size=32,
class_mode='categorical',
subset='training' # 훈련 데이터
)
validation_generator = train_datagen.flow_from_directory(
base_dir,
target_size=(28, 28),
batch_size=32,
class_mode='categorical',
subset='validation' # 검증 데이터
)
# 데이터 확인
print(f"Classes found: {train_generator.class_indices}") # {'circles': 0, 'squares': 1, 'triangles': 2}
print(f"Training samples: {train_generator.samples}") # Training samples: 240
print(f"Validation samples: {validation_generator.samples}") # Validation samples: 60
# # 이미지 데이터 전처리
# datagen = ImageDataGenerator(
# rescale=1./255, # 픽셀 값을 0~1 범위로 조정
# rotation_range=20, # 이미지 회전
# width_shift_range=0.2, # 수평 방향 이동
# height_shift_range=0.2, # 수직 방향 이동
# shear_range=0.2, # 전단 변형
# zoom_range=0.2, # 확대 축소
# horizontal_flip=True,# 수평 뒤집기
# fill_mode='nearest'
# )
### CNN ; model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 3)),
MaxPooling2D(2, 2),
Dropout(0.2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Dropout(0.2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Dropout(0.3),
Flatten(),
Dense(128, activation='relu'),
Dense(3, activation='softmax') # 클래스 수에 따라 변경 (3개 클래스: circles, squares, triangles)
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
epochs = 20
# 모델 학습
# history = model.fit(
# X_train, y_train,
# validation_data=(X_val, y_val),
# epochs=epochs,
# batch_size=32
# )
# 모델 학습
history = model.fit(
train_generator,
validation_data=validation_generator,
epochs=20,
)
# 모델 평가
# test_loss, test_acc = model.evaluate(X_val, y_val, batch_size=32)
# print(f'\nValidation accuracy: {test_acc}')
# 모델 평가
test_loss, test_acc = model.evaluate(validation_generator)
print(f"Validation Loss: {test_loss}")
print(f"Validation Accuracy: {test_acc}")
import matplotlib.pyplot as plt
# 정확도 그래프
plt.figure(figsize=(10, 5))
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
# 손실 그래프
plt.figure(figsize=(10, 5))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()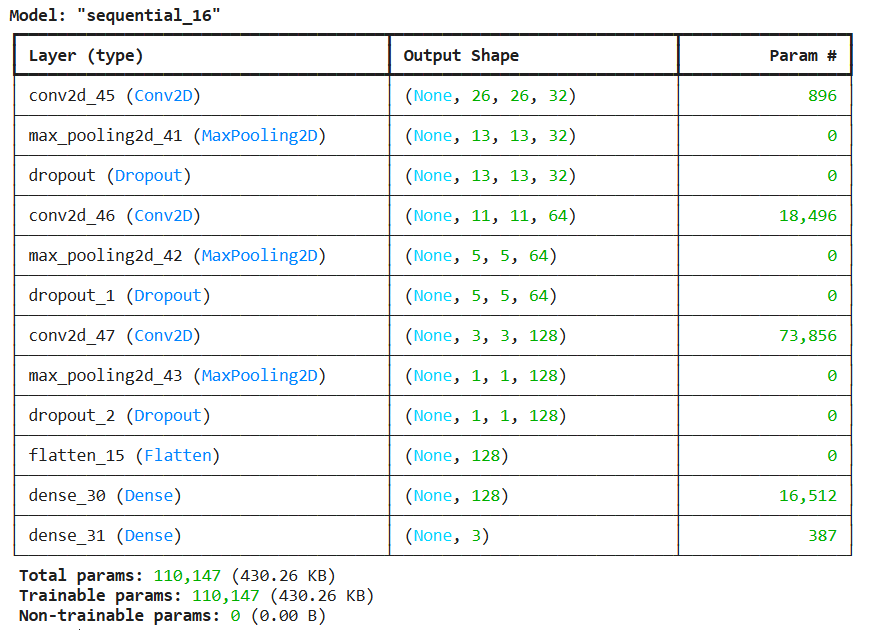

'AI, 논문, 데이터 분석' 카테고리의 다른 글
| [클라우드 컴퓨팅] Azure 개념 (리소스 그룹, Entra ID/Tenant, 사용자 계정) (0) | 2025.01.06 |
|---|---|
| [클라우드 컴퓨팅] [Azure 실습 1] 프로젝트 시작 (0) | 2025.01.06 |
| [Scanpy] 설치 및 실행 (1) | 2024.12.14 |
| conda 가상환경 생성 및 R 실행 (3) | 2024.11.28 |
| [Linux] 하드 링크 vs 소프트 링크 (0) | 2024.11.26 |



